1. El programa ensamblador
El programa ensamblador es la herramienta que realiza la traducción de un
fichero que contiene instrucciones para el procesador del estilo mov
%eax, %ebx a su correspondiente representación como secuencia de
ceros y unos. Este programa por tanto sabe cómo codificar todas y cada una
de las operaciones posibles en el procesador, así como sus operandos, modos
de direccionamiento, etc.
La entrada al programa ensamblador (de ahora en adelante simplemente
ensamblador) es un fichero de texto plano que contiene un programa o
secuencia de instrucciones a ejecutar por el procesador. El lenguaje en
el que se escriben estas instrucciones se conoce como lenguaje
ensamblador. Un mismo procesador puede tener diferentes
programas ensambladores con diferentes lenguajes de entrada, pero todos
ellos producen idéntico código (o lenguaje) máquina.
El lenguaje ensamblador no sólo permite utilizar los nombres de las
instrucciones, operandos y modos de direccionamiento, sino que también
permite especificar etiquetas y definir porciones de memoria para
almacenar datos.
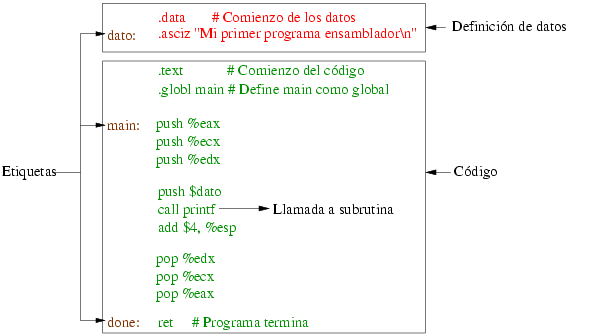
La figura 1.1 muestra un fichero que contiene
un programa escrito en ensamblador:
Un programa consta de varias partes diferenciadas. La palabra
.data es una directiva y comunica al
ensamblador que a continuación se define un conjunto de
datos. El programa tan sólo tiene un único dato que se
representa como una secuencia de caracteres. La línea .asciz,
también una directiva, seguida del string entre comillas es la que instruye
al ensamblador para crear una zona de memoria con datos, y almacenar en
ella el string que se muestra terminado por un byte con valor
cero. Nótese que el efecto de la directiva .asciz
no se traduce en código sino que son órdenes para que el ensamblador haga
una tarea, en este caso almacenar un string en memoria.
Antes de la directiva .asciz se incluye la palabra
dato seguida por dos puntos. Esta es la forma de definir una
etiqueta que luego se utilizará en el código para
acceder a estos datos.
La línea siguiente contiene la directiva .text que denota el
comienzo de la sección de código. Nótese que todas las directivas tienen
como primer carácter un punto. La línea con la
directiva .globl main comunica al ensamblador que la etiqueta
con nombre main será globalmente accesible desde otro programa.
A continuación se encuentran las instrucciones en ensamblador propiamente
dichas. Se pueden ver las instrucciones push parar almacenar
un operando en una zona específica de memoria que se denomina la pila.
Al comienzo del código se define la etiqueta main. Esta
etiqueta identifica la posición en por la que el procesador va a empezar a
ejecutar. Hacia el final del código se puede ver una segunda etiqueta con
nombre done.
Una vez creado el fichero de texto con el editor y guardado con el
contenido de la figura superior y con nombre programa.s, se ejecuta el
compilador. Para ello primero es preciso arrancar una ventana con el
intérprete de comandos y estando situados en el mismo directorio en el que
se encuentra el fichero programa.s ejecutar el
comando:
gcc -o programa programa.s
El compilador realiza una tarea similar a la de un compilador de un
lenguaje de alto nivel como Java. Si hay algún error en el programa se
muestra la línea y el motivo. Si todo es correcto, se genera un fichero con
el resultado. En el ejemplo, se ha instruido al ensamblador, por medio de
la opción -o programa que el resultado lo deposite en el
fichero programa.
En el caso de tener el código escrito en varios ficheros que deben
combinarse para obtener un único programa, la línea anterior se modifica
incluyendo todos los ficheros con extensión
.s necesarios.
Si no ha habido ningún error, el fichero programa está
listo para ser ejecutado por el procesador. Para ello simplemente se ha de
teclear su nombre en el intérprete de comandos (en la siguiente línea, la
palabra shell$ representa el mensaje que imprime siempre
el intérprete de comandos):
shell$ programa
Mi Primer Programa Ensamblador
shell$
Volvamos al código para analizar detenidamente lo que acabamos de
ejecutar. La etiqueta main marca el punto en el código en el
que el programa comienza a ejecutar. Todo programa debe seguir el siguiente
patrón:
.data # Comienzo del segmento de datos
<datos del programa>
.text # Comienzo del código
.global main # Obligatorio
main:
<Instrucciones>
ret # Obligatorio
Nótese que se pueden incluir todo tipo de comentarios utilizando el
carácter '#'. Todo lo que se escriba desde este carácter hasta el final de
la línea es ignorado por el compilador. Basado en este patrón, el programa
anterior ha ejecutado las instrucciones:
push %eax
push %ecx
push %edx
push $dato
call printf
add $4, %esp
pop %edx
pop %ecx
pop %eax
ret
Las primeras tres instrucciones depositan los valores de los registros
%eax, %ecx y %edx en la zona de
memoria denominada la pila. Las tres instrucciones siguientes se encargan
de poner la dirección del string también en la pila (instrucción
push), invocar una rutina externa que imprime el string
(instrucción call) y sumar una constante al registro
%esp. Finalmente, las tres últimas instrucciones restauran el
valor original en los registros previamente guardados en la pila.
La subrutina printf modifica el contenido de los registros
%eax, %ecx y %edx. Por tanto, antes
de llamar a esta rutina es necesario salvar su contenido en memoria (en
este caso en la pila) y restaurar su valor al terminar. Con las
instrucciones de push al comienzo y pop al final
se garantiza que el programa termina con idénticos
valores con los que comenzó la ejecución en los registros.
2. Traducción de lenguaje ensamblador a lenguaje máquina
El programa ensamblador, aparte de traducir de lenguaje ensamblador a
lenguaje máquina, también puede mostrar por pantalla el resultado de la
codificación de las instrucciones y datos en binario
Para la resolución de este ejercicio se trabaja con el siguiente programa que debe ser guardado en un
fichero con nombre sumados.s y cuyo código se
muestra en la figura 1.2.
El compilador o ensamblador es el programa que traduce este fichero a un
fichero ejecutable en lenguaje máquina. Sin embargo, se puede ejecutar
este programa con la orden para que, en lugar de generar un ejecutable,
muestre por pantalla el resultado de la traducción de ensamblador a
lenguaje máquina. Esto se consigue incluyendo la opción
-Wa,-a (nótese la ausencia de espacios en blanco). El
comando para ensamblar el programa y ver el resultado por pantalla es:
gcc -Wa,-a -o <ejecutable> <fichero.s>
donde <ejecutable> se debe reemplazar por el nombre del
fichero ejecutable a crear y <fichero.s> por el del
fichero que contiene el código ensamblador.
El compilador muestra por pantalla el resultado del proceso de traducción a
lenguaje máquina en un formato específico. Para analizar en detalle este
listado se puede capturar el resultado en un fichero y visualizarlo
mediante un editor. Para obtener un fichero que contenga el resultado
producido por el compilador, es preciso ejecutar el comando anterior
añadiendo al final el sufijo > listado.txt.
Al ejecutar este comando el compilador no muestra ningún dato por
pantalla y únicamente el intérprete de comandos escribe de nuevo el
prompt. Sin embargo, en el directorio actual se ha creado un fichero
listado.txt. Este fichero se puede abrir y ver su
contenido con el editor.
El listado producido por el compilador está organizado por columnas. El
compilador muestra el código del fichero en la parte izquierda, y en la
parte derecha incluye tres columnas de números. En la primera columna se
muestra el número de línea del fichero original. Los números incluidos en
la segunda y tercera columna están escritos en hexadecimal. La segunda
columna muestra en hexadecimal el número del primer byte de la
codificación que se muestra en la tercera columna. El número de la
segunda columna se puede obtener sumando al número de esta columna de la
línea anterior, el número de bytes de la tercera columna. La codificación
comienza a partir del byte 0 y se van almacenando los bytes en posiciones
correlativas.
En la tercera columna se muestra el resultado de la codificación de cada
línea (también en hexadecimal). Cuando dicha codificación ocupa más de
una línea, se repite en la primera columna el número de línea incluyendo
el valor de los siguientes bytes.
A la vista del código mostrado por el compilador, responder a las siguientes
preguntas:
¿Cuántos bytes ocupa la traducción a lenguaje máquina de la línea 3?
En la tercera columna de la línea con el número 5 aparece el número
0x61FCFFFF. ¿Cómo se ha obtenido este número?
En la línea 6 se utiliza la orden .space seguida de un
número. ¿Qué significa este número? (puedes probar a modificarlo y
ver qué efecto tiene en el listado que muestra el compilador).
A la vista del resultado de la traducción de la línea 3, ¿cuál es el
código ASCII en hexadecimal que representa el símbolo
“=”?
¿Cuál es la codificación en hexadecimal de la instrucción push
%eax?
La instrucción push seguida de un registro
se codifica con 8 bits. El procesador dispone de ocho registros con
nombres %eax, %ebx, %ecx,
%edx, %esi, %edi, %ebp y
%esp. Deducir con esta información qué bits del byte que
codifica la instrucción son los que más probablemente se utilicen
para codificar el registro (se permite modificar el código).
¿Por qué crees que la codificación de las instrucciones en las líneas
20 y 21, a pesar de ser ambas del tipo push tiene
diferente tamaño?
La instrucción add %eax, result se codifica con 6
bytes. El procesador dispone de ocho registros con nombres
%eax, %ebx, %ecx,
%edx, %esi, %edi,
%ebp y %esp. Deducir con esta información
qué bits de los seis bytes que codifican la instrucción son los que
más probablemente se utilicen para codificar el registro (se permite
modificar el código).
La instrucción add $8, %esp se codifica con tres
bytes. ¿Cuántos bits se utilizan para codificar la constante que
aparece como primer operando de la suma?
Explica qué sucede con la codificación de la instrucción anterior si la
constante del primer operando es mayor que 127.
Para definir un string, además de la directiva .asciz
que se utiliza en la línea 3, el ensamblador también permite la
directiva .ascii. ¿En qué se diferencian?
En la línea 6 se utiliza la directiva .space. Esta
directiva permite que en lugar de ir seguida de un número, vaya
seguida de dos números separados por comas. ¿Cuál es el efecto del
segundo número?
¿Cuál es la longitud en bytes de la codificación de los datos del programa?
¿Cuál es la longitud en bytes de la codificación del código del programa?
En las líneas finales del listado se incluye una sección con título
DEFINED SYMBOLS. Esta sección consta
de cinco líneas que comienzan por el nombre del fichero seguido de
dos puntos, seguido de un número, luego aparece la palabra
.data o .text, a continuación un número, y
termina con un nombre. ¿Qué crees que significa el número que aparece
en penúltimo lugar?
La representación en lenguaje máquina de la instrucción mov
valor1, %eax debe contener en su interior un conjunto de bits
que codifique el símbolo valor1. ¿Qué bits de su
codificación se utilizan para esto? (se permite modificar el código y
se sugiere consultar la información de la sección DEFINED
SYMBOLS al final del listado).
La última sección del listado lleva por título UNDEFINED
SYMBOLS. ¿Por qué crees que esta sección incluye el símbolo
printf?
La función printf, de la biblioteca de funciones
auxiliares, incorpora el código necesario para imprimir números enteros
(en decimal, hexadecimal u octal), números en coma flotante, cadenas de
texto, etc. Para ello tan sólo se necesita especificar los datos a
imprimir y su formato.
El primer parámetro que se pasa se llama cadena de
formato. Esta cadena contiene el mensaje a escribir y, además,
permite indicar el formato en el que se deben imprimir ciertos parámetros
adicionales. Por ejemplo, si se invoca con los tres parámetros
"%s tiene %d años\n", "María" y 18 escribe
“María tiene 18 años”. En la cadena de formato,
el símbolo %s (de string) indica que el parámetro siguiente a
la cadena es una cadena de texto (su dirección en memoria). Análogamente,
%d (de decimal) en la cadena de formato indica que en ese
lugar se debe imprimir en formato decimal el siguiente parámetro que es un
número. La propia rutina se encarga de transformar el número en la cadena
de texto pertinente. El símbolo “\n” al final de
la cadena de formato representa el carácter de fin de línea. En caso de
querer imprimir el símbolo \ se debe utilizar
“\\”
Lo más importante de esta función es proporcionar tantos parámetros
adicionales como símbolos de formato se especifican en la cadena.
En la Tabla 1.1 se muestran los símbolos que se
pueden incluir en la cadena de formato y su interpretación.
Tabla 1.1. Símbolos utilizados en el formato de printf
| Formato |
Significado |
%c |
Imprime el carácter ASCII correspondiente |
%d, %i
|
Conversión decimal con signo de un entero |
%x, %X
|
Conversión hexadecimal sin signo |
%p |
Dirección de memoria (puntero) |
%e, %E
|
Conversión a coma flotante con signo en notación científica
|
%f |
Conversión a coma flotante con signo, usando punto decimal
|
%g, %G
|
Conversión a coma flotante, usando la notación que requiera menor
espacio
|
%o |
Conversión octal sin signo de un entero |
%u |
Conversión decimal sin signo de un entero |
%s |
Cadena de caracteres (terminada en'\0') |
%% |
Imprime el símbolo % |
La elección entre “x” o
“X” simplemente determina si las letras que
puedan aparecer deben ser minúsculas o mayúsculas.
Para ejecutar esta función se deben depositar en la pila todos los
parámetros necesarios en el orden correcto. Justo antes de la llamada a
printf (instrucción call printf), en la cima de la pila debe
estar la dirección de la cadena de formato y a continuación (en las
posiciones siguientes de la pila) todos los parámetros adicionales en el
orden en que se utilizan en dicha cadena. La figura 1.3 ilustra cómo se han de disponer los parámetros
en la pila para llamar a la rutina e imprimir el ejemplo mencionado
anteriormente.
Atención: La llamada a la función printf
modifica el valor de los registros %eax, %ecx y
%edx, por lo que todo valor que se tenga en dichos registros
antes de la llamada, si se quieren conservar, se deben guardar en la pila y
restaurarlos después.
4. Distancia entre dos etiquetas
Las etiquetas en lenguaje ensamblador se utilizan para poder referirse a
puntos concretos en la definición de datos o de código. Si existe una
etiqueta con nombre label, la dirección de memoria a la que se
refiere se obtiene mediante la expresión $label. Además, el
contenido de dicha dirección de memoria se obtiene utilizando el nombre de
la etiqueta label sin prefijo.
Un programa contiene en su sección de datos la
definición que se muestra en la figura 1.4.
Escribir el programa distancia.s que almacene en las
posiciones de memoria con etiquetas v1, v2 y
v3 las direcciones a las que se refieren las etiquetas
ms1, ms2 y ms3. Además, en la
posición de la etiqueta v2_v1 debe almacenar la distancia
entre las direcciones de ms1 y ms2, y en la
posición de la etiqueta v3_v2, la distancia entre las
direcciones de ms3 y ms2. Al mismo tiempo que
calcula estos valores, y mediante llamadas a la función
printf, el programa debe imprimir para cada uno de los cinco
resultados una línea tal y como se muestra a continuación:
Etiqueta con valor 0x80495f3
Etiqueta con valor 0x804960f
Etiqueta con valor 0x8049623
Distancia = 28
Distancia = 20
Los valores de las direcciones de memoria que se imprimen por pantalla en
las tres primeras líneas no tienen por qué coincidir exactamente. El
programa sí debe imprimir idénticos valores para la distancia.
5. Volcado de valores de registros por pantalla
La subrutina printf imprime un número en hexadecimal cuando en
el string de formato aparecen los caracteres
“%x”.
Dada la siguiente sección de datos que
se muestra en la figura 1.5:
Escribir el programa regdump.s que muestre el
contenido en ese preciso instante de la ejecución de los registros
%eax, %ebx, %ecx y %edx
por pantalla tal y como se muestra a continuación (los valores que se
imprimen seguramente sean diferentes):
Registro: 0xbfe11b94
Registro: 0xa08ff4
Registro: 0x8f8d24
Registro: 0x1
6. ASCII en mayúscula o minúscula
Los símbolos tales como letras, dígitos, etc. se representan mediante el
código ASCII que asocia
un número entre 0 y 255 a cada símbolo utilizando un byte para su
codificación. Este sistema permite comparar entre sí los caracteres como
si fueran números naturales, puesto que se compara en realidad sus
respectivos códigos ASCII.
Escribir el programa comprobarCaracter.s que comprueba si el
carácter almacenado en la posición de memoria que denota la etiqueta
caracter es una letra mayúscula, minúscula o no es un carácter
alfabético, deposita un entero de 32 bits en la posición a la que apunta la
etiqueta resultado e imprime el mensaje correspondiente por
pantalla.
El programa debe comprobar los siguientes casos:
Si caracter está en el rango
[“a”-“z”] (minúscula) se deposita el valor 1
en la posición resultado e imprime “l es una letra
minúscula” (donde “l” es la letra almacenada en
caracter).
Si caracter está en el rango
[“A”-“Z”] (mayúscula) se deposita el valor 2
en la posición resultado e imprime “L es una letra
mayúscula” (donde “L” es la letra almacenada en
caracter).
Si caracter está fuera de los dos intervalos anteriores
(carácter no alfabético) se deposita el valor -1 en la posición
resultado e imprime “el valor dado no es un carácter
alfabético”.
El programa debe incluir la siguiente definición de datos exactamente tal y como se
muestra en la figura 1.6.
|