| 7.9.3. Tree of Strings | ||
|---|---|---|
 | 7.9. Activities |  |
| 7.9.3. Tree of Strings | ||
|---|---|---|
| | 7.9. Activities | |
A C program needs to store an undetermined number of strings. The selected data structure is a binary tree in which each node stores one string. Furthermore, the tree has the property that the word stored in a node follows lexicographically those in the left sub-tree and precedes those in the right sub-tree. The following figure shows an example of this data structure.
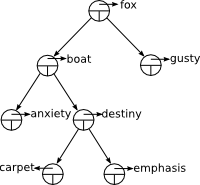
The application needs to manipulate several sets of words independently.
Define the needed data structures to manipulate these trees.
Define the prototypes of the following functions:
Function that creates a new empty set.
Function that searches a word in a set and returns it (this word can be modified in the future).
Function that inserts a word in a tree. If it exists already, nothing is done.
Function that destroys a full tree.
Function that deletes a word from the tree.
Write the method main containing a loop and
using the function getline reads from the keyboard a string
and inserts it alternatively in two trees. The program must stop when
getline rerutns the value NULL.
Divide the work in teams so that each of them implements
either the search method, the insertion or the deletion of the whole
tree. The library function strcmp receives two strings and
returns an integer that is less than, equal to or greater than zero if
the first string preceds, is identical or follows the second
lexicographically.
Implement the function to delete a string.
Answer the following questions:
If we compare this data structure with a linked list of words, Which data structure offers the most efficient insertion?
How do these two data structures compare with respect to the search?
Two trees contain exactly the same words. Does this mean they have identical structure?
If in the C application using these functions, 99% of the operations are search operations, Which improvement would you propose in the data structure to gain efficiency?
| |  | |
| 7.9.2. Integer linked list |  | 7.9.4. Using linked lists |